









たとえば、Wordファイルの資料から
- 名前を差し替える。
- 日付を差し替える。
- 表記ゆれを訂正する。
みたいな作業ってわりとあると思うんです。
1つのWordファイルに対してだったら 、「Ctrl + H 」で置換すれば良いと思います。
でも、ファイル数や訂正箇所が多くなると、いちいちファイルを開いて…訂正して…
考えるだけで面倒くさいですよね。
そこで、今回は勉強も兼ねてPythonで複数のWordファイルから任意の文字列を置換する方法をまとめました。
やり方
「python-docx」ライブラリをインストールする
まず、PythonでWordファイルを操作するには、外部ライブラリの「python-docx」が必要です。
pipコマンドを使ってインストールします。
!pip install python-docxプロジェクトフォルダを作る
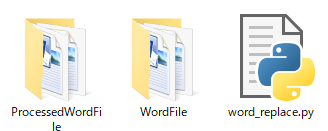
そして、以下の構成のフォルダを作ります。
WordReplacement
├ ProcessedWordFile ←変換したWordファイルが出力されるフォルダ
├ WordFile ←変換したいWordファイルを入れるフォルダ
│
└ word_replace.py ←Pythonの実行ファイル最終的にはこんな感じ↓になるイメージです。
Pythonのプログラムを書く
word_replace.pyの中身を書いていきます。
今回は、置換したい文字列を配列「replace_string」に格納する方法にしました。
ここでは
- 「鈴木花子」→「山田太郎」にする。
- 西暦「20○○年」→「2021年」にする。
- 和暦を「令和3年」にする。
- 「ヴァイオリン」の表記ゆれを統一する
みたいな用途を想定した記述になっています。
# 必要なライブラリをインポートする
from pathlib import Path
import glob
import docx
import re
import os
# 置き換えるテキストを設定-------------------------------
# 置き換える年を定義
year = '2021年'
wareki = '令和3年'
# 置換したい文字列をlistで定義する
replace_string = [
# 人名
['鈴木花子', '山田太郎'],
# 日付
['20..年', year],
['平成.年', wareki],
['平成..年', wareki],
['令和.年', wareki],
['令和..年', wareki],
# 表記ゆれ
['バイヨリン', 'ヴァイオリン'],
['バイオリン', 'ヴァイオリン']
]
# 置換用のスクリプト-------------------------------
# for文で「WordFile」フォルダの中にある、「全てのWord(docx)ファイル」のパスを取得して処理を行う。
for x in glob.glob("./WordReplacement/WordFile/*.docx"):
# 取得したWord(docx)ファイルのパスを変数word_file_pathに代入する
word_file_path = Path(x)
# Word文書のdocxファイルのドキュメント要素を読み込み、変数「doc」に代入する
doc = docx.Document(word_file_path)
# 取得したWord(docx)ファイルのファイル名を変数file_nameに代入する
file_name = os.path.basename(word_file_path)
# 置換したい文字列がファイル名にも含まれる場合は置換
for i in range(len(replace_string)):
file_name = re.sub(
replace_string[i][0], replace_string[i][1], file_name)
# ターミナルの出力結果を見やすくするための線をprint関数で表示する
print(f'\n----------{file_name}----------')
# 段落の個数をprint関数で表示する
print(f'段落の個数:{len(doc.paragraphs)}\n')
# for文で置換したい文字列を置換する処理
num = 0
for paragraph in doc.paragraphs:
num += 1
# このparagraphに置換するテキストが含まれるか判定する
inclusion_determination = False
for i in range(len(replace_string)):
if re.search(replace_string[i][0] , paragraph.text):
#置換する文字列が含まれる場合は、変数inclusion_determinationhにTrueを代入する
inclusion_determination = True
#置換前のテキストを変数 before_paragraphに代入する
before_paragraph = paragraph.text
# 置換したい文字列の置換をする
for i in range(len(replace_string)):
paragraph.text = re.sub(replace_string[i][0], replace_string[i][1], paragraph.text)
# 置換したい文字列が含まれるparagraphのみprint関数で表示
# (意図しない置換をしていないかチェック用)
if inclusion_determination == True :
print(f'{num}:{before_paragraph}\n → {paragraph.text}')
# 置換したWord(docx)ファイルを「ProcessedWordFile」フォルダに名前を付けて保存する
doc.save(f'./WordReplacement/ProcessedWordFile/{file_name}')使ってみる
まず、変換したいWordファイルを「WordFile」にぶち込みます。
ここでは、以下の2種類のWordファイルを作ってみました。


word_replace.pyを実行します。
一気に置換されたWordファイルが「ProcessedWordFile」に出力されます。
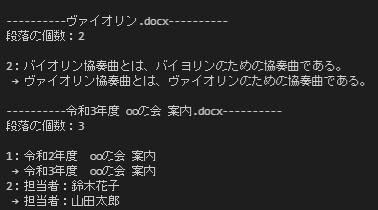


置換されてますね!
…しかし、よく見ると太字などの書式設定がリセットされています。
Paragraphオブジェクトに.textを使うと、書式設定が失われるようです…。
元ファイルで書式設定を変更していた場合は、嬉しくないですね…。
書式設定を保ちたい
一応、解決策を見つけました。
ParagraphオブジェクトをさらにRunオブジェクトに分割すると、書式設定を保ったまま置換ができます。
Runオブジェクトは、Paragraphオブジェクトを書式設定と文字と数字ごとに区切ったかたまりです。
つまり、この部分を
# 置換したい文字列の置換をする
for i in range(len(replace_string)):
paragraph.text = re.sub(replace_string[i][0], replace_string[i][1], paragraph.text)こういう感じにすれば
# 置換したい文字列の置換をする(書式設定を保つ)
for run in paragraph.runs:
for i in range(len(replace_string)):
run.text = re.sub(replace_string[i][0], replace_string[i][1], run.text)書式設定を保ったままテキストの置換ができます。

…しかし、こちらの方法にも弱点があります。
それは、Runオブジェクトは、文字と数値でも区切られてしまうので
'令和2年'みたいな文字と数字が入り混じった文字列は
令和
2
年みたいに区切られてしまって置換できていません。
もちろん、replace_stringには文字は文字、数字は数字で指定すれば、今回の例では問題無いかもしれません。
ただ、もっと長い文章や複数のファイルを置換する場合
'令和2年'の「2」を「3」にしたくて「2」だけを指定すると、他の場所で使われている「2」まで置換されて事故が起こりかねません。
追記:よりよい方法
「この問題の解決方法はちょっと分かりません…良い方法を知っている方がいたら教えてください…。」とQiitaに同様の投稿をしたところ…
コメント欄で、より良い書き方を教えてくださった方がいます!!(T▽T)
そちらの方が、より様々なケースに対応できる書き方になっています!ありがたい…!
ぜひ、この続きはQiitaのコメント欄も参考にしてみてください!

おまけ
(僕を含めて)Pythonにバリバリ精通している人ばかりでないと思うので、個人的に詰まったポイントを紹介しておきます。
ファイルパスには注意する
ファイルパス(ファイルがある場所)の指定が上手くいってないと上手く動きません。
ここらへん↓の記述ですね。
# for文で「WordFile」フォルダの中にある、「全てのWord(docx)ファイル」のパスを取得して処理を行う。
for x in glob.glob("./WordReplacement/WordFile/*.docx"): # 置換したWord(docx)ファイルを「ProcessedWordFile」フォルダに名前を付けて保存する
doc.save(f'./WordReplacement/ProcessedWordFile/{file_name}.docx')パスは、確認したいファイルをShift+右クリックして、出てくる項目の中から「パスのコピー」で取得できます。
VScodeなら「Shift+Alt+C」で取得できます。
「*」は正規表現のワイルドカードです。
文字列の置換には、replaceではなくre.subを使う
文字列の置換はreplaceではなく、re.subを使っています。
なぜなら、変換前の文字列に「’20..年’」みたいに正規表現を使いたいからです。
※文字列を包含判定に「in演算子」ではなく「re.search」を使っているのもそのためです。
参考記事など